Nested Data in DataMine
03 Nov 2014After joining Turn, I started to work on DataMine, a peta-byte scale data warehouse built upon Hadoop. One of the most important features of DataMine is that it can effectively support the nested data structure.
 Comparing with the traditional relational data model, the nested relational data model allows the value in a table to be a set or a hierarchical structure. While stored in the database it cannot be simply normalized, instead it is depicted in the non-first normal form (i.e., non-1NF). In other words, the constraint that all domains must be atomic is not satisfied. Clearly it is a drawback if the data needs updating frequently. Whereas the nested relational data model makes the data representation more natural and efficient, and importantly it can eliminate join operations while reading. From this point of view the nested data structure can work well with data warehouse, where OLAP (OnLine Analytical Processing) is more common than OLTP (OnLine Transaction Processing).
Comparing with the traditional relational data model, the nested relational data model allows the value in a table to be a set or a hierarchical structure. While stored in the database it cannot be simply normalized, instead it is depicted in the non-first normal form (i.e., non-1NF). In other words, the constraint that all domains must be atomic is not satisfied. Clearly it is a drawback if the data needs updating frequently. Whereas the nested relational data model makes the data representation more natural and efficient, and importantly it can eliminate join operations while reading. From this point of view the nested data structure can work well with data warehouse, where OLAP (OnLine Analytical Processing) is more common than OLTP (OnLine Transaction Processing).
DataMine exploits a nested relational data model. Particularly it allows the domain of one attribute of a table to be another table. One typical use case with DataMine is to store the on-line user profiles in a table with nested tables. Each record is composed of many user attributes, such as ID, time stamp, campaign information etc. Some attributes like campaign information can be further nested tables. An example can be found below.
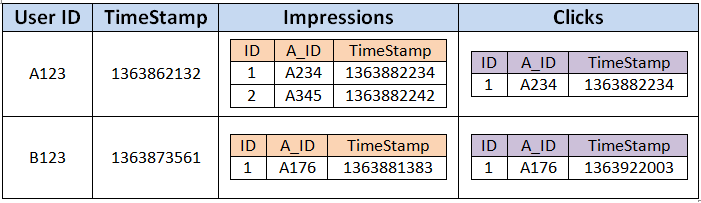
To enable an efficient data access or query processing, DataMine implements an unnesting operation that flattens a record into a set of records. Thus the existing relational query execution techniques can be applied. Actually the unnesting operation tends to transform the table with nested data structure from non-1NF to 1NF. For example, the table above can be unnested as the following result.

When the table sizes become very large, it is not efficient to support JOIN between tables. This can be one reason why fewer tables are strictly normalized with their sizes increasing. Keeping everything within a single table can eliminate some JOINs. On the other hand, the correlation analytics at the record level is possible. DataMine allows JOIN between nested tables within a query through implementing special LIST functions.
A table in DataMine can have billions of records, and the nested table of a record can have millions of nested table records. Scalability is always the first consideration in the design and development. Now, DataMine stores its data in the HDFS (HaDoop File System). Depending upon the requirements, the data can be in row based or column based. Columnar store is a good fit for the use cases where partial deserialization is common, whereas row-based store can keep a performance balance between reading and writing.
From my experience, many applications in the big data era share some common features:
- Data normalization is not necessary. Nested data model is a natural choice when a hierarchy gets involved in the data structure.
- The data are written once and read multiple times. In other words, the data updating is not often a requirement.
- The complex data analytics can be implemented efficiently through applying JOIN operations among nested tables inside a record.
Certainly DataMine is a good fit in these applications.