03 Nov 2014
After joining Turn, I started to work on DataMine, a peta-byte scale data warehouse built upon Hadoop. One of the most important features of DataMine is that it can effectively support the nested data structure.
 Comparing with the traditional relational data model, the nested relational data model allows the value in a table to be a set or a hierarchical structure. While stored in the database it cannot be simply normalized, instead it is depicted in the non-first normal form (i.e., non-1NF). In other words, the constraint that all domains must be atomic is not satisfied. Clearly it is a drawback if the data needs updating frequently. Whereas the nested relational data model makes the data representation more natural and efficient, and importantly it can eliminate join operations while reading. From this point of view the nested data structure can work well with data warehouse, where OLAP (OnLine Analytical Processing) is more common than OLTP (OnLine Transaction Processing).
Comparing with the traditional relational data model, the nested relational data model allows the value in a table to be a set or a hierarchical structure. While stored in the database it cannot be simply normalized, instead it is depicted in the non-first normal form (i.e., non-1NF). In other words, the constraint that all domains must be atomic is not satisfied. Clearly it is a drawback if the data needs updating frequently. Whereas the nested relational data model makes the data representation more natural and efficient, and importantly it can eliminate join operations while reading. From this point of view the nested data structure can work well with data warehouse, where OLAP (OnLine Analytical Processing) is more common than OLTP (OnLine Transaction Processing).
DataMine exploits a nested relational data model. Particularly it allows the domain of one attribute of a table to be another table. One typical use case with DataMine is to store the on-line user profiles in a table with nested tables. Each record is composed of many user attributes, such as ID, time stamp, campaign information etc. Some attributes like campaign information can be further nested tables. An example can be found below.
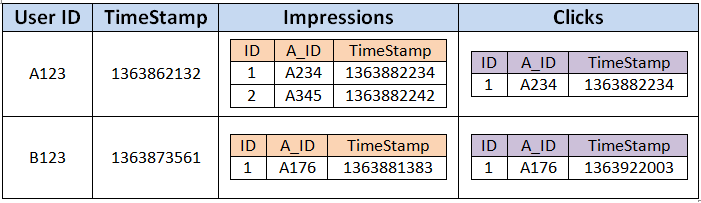
To enable an efficient data access or query processing, DataMine implements an unnesting operation that flattens a record into a set of records. Thus the existing relational query execution techniques can be applied. Actually the unnesting operation tends to transform the table with nested data structure from non-1NF to 1NF. For example, the table above can be unnested as the following result.

When the table sizes become very large, it is not efficient to support JOIN between tables. This can be one reason why fewer tables are strictly normalized with their sizes increasing. Keeping everything within a single table can eliminate some JOINs. On the other hand, the correlation analytics at the record level is possible. DataMine allows JOIN between nested tables within a query through implementing special LIST functions.
A table in DataMine can have billions of records, and the nested table of a record can have millions of nested table records. Scalability is always the first consideration in the design and development. Now, DataMine stores its data in the HDFS (HaDoop File System). Depending upon the requirements, the data can be in row based or column based. Columnar store is a good fit for the use cases where partial deserialization is common, whereas row-based store can keep a performance balance between reading and writing.
From my experience, many applications in the big data era share some common features:
- Data normalization is not necessary. Nested data model is a natural choice when a hierarchy gets involved in the data structure.
- The data are written once and read multiple times. In other words, the data updating is not often a requirement.
- The complex data analytics can be implemented efficiently through applying JOIN operations among nested tables inside a record.
Certainly DataMine is a good fit in these applications.
19 Sep 2014
Recently an article in readwrite.com drew my attention. It talks about PHP, a programming language created in 1994. It reminds me of those days when I studied PHP, making me think a lot about the programming languages and the ideas underneath. (Interestingly both PHP and Hadoop employ an elephant in the logo)
The first programming language that I learned is Pascal. Since then, there have been a long list of programming languages that I have ever used. Few of them were taught in my college such as Pascal, C and ASM. Others were mostly self taught, when they were regarded as necessary. For instance, when I did research on the high availability systems, I worked on some programs in Erlang, a programming language not commonly recognized.
The story of PHP might sound a little funny. PHP, as you may know, is a scripting language that allows programmers to build dynamic Web pages. Clearly, it doesn’t seem right if you apply it in the field of, let’s say, machine learning.  When I was a senior at college, one of the post-doctors in the lab where I volunteered assigned me a job: to implement a machine learning algorithm in PHP. According to her, the program would be easily deployed as a Web service if it were implemented in PHP. I was too fresh to think about it again before taking action. In the following weeks, I tried my best to learn and use PHP to implement the algorithm. However, no matter how hard I tried, the program I got did not work: it was too slow to get completed. In the end I had to re-implement the algorithm in C, which proved to be the right choice.
When I was a senior at college, one of the post-doctors in the lab where I volunteered assigned me a job: to implement a machine learning algorithm in PHP. According to her, the program would be easily deployed as a Web service if it were implemented in PHP. I was too fresh to think about it again before taking action. In the following weeks, I tried my best to learn and use PHP to implement the algorithm. However, no matter how hard I tried, the program I got did not work: it was too slow to get completed. In the end I had to re-implement the algorithm in C, which proved to be the right choice.
The bright side of this story is that the effort I took on PHP was not a waste. I learned how to build a website with PHP. I am also impressed by its simplicity and flexibility. PHP may not be perfect, but it is simple and powerful enough in most cases. Furthermore, learning how PHP works also deepened my understanding of web programming. Other lessons that I learned about programming also include:
- Every programming language has its pros and cons. There is no such a thing as ‘silver bullet’.
- It is necessary to have a thorough understanding of problem in the field in order for choosing the right programming language.
- There is a huge gap between knowing a language and using it well. No shortcut! But keeping practicing can always lead us closer to be a master.
The programming language is quite different from the human language. Rather than often a communication vehicle, the programming language is more like a tool for solving computational problems. Obviously as there can be more than one solution or different ways to attack the problem, no programming language would be the ONE. In some scenario, one may be better than the other, but in others not necessarily. Sometimes it is amusing to see people arguing against each other as to which programming language is the best. In many cases, people simply ignore the problems the languages try to solve, instead they would rather pay more attention to the features or functionalities. Remember I was one of them once upon a time, when I started to learn Java. I thought Java would replace C++ or C some day as it is a write-once-run-anywhere language. However, the day never comes because Java and C++ are excellent only in some particular fields.
Instead of focusing on the programming languages, I believe it is more helpful to think of the problem. Why are there more than one programming languages to attack the same problem? Is it a tricky problem? What is the challenge behind? Is there anything we can do to improve any exiting tool? Not only does thinking in this way pull us out of the pointless argument, but leads us to better ourselves.
02 Sep 2014
When I was in the graduate school of ASU, I worked with my Ph.D adviser, Dr. K. Selçuk Candan on data integration. One goal of my work was to develop efficient algorithms to capture conflicts in the data integration and provide effective schemes to resolve them. In our proposal, we represent the integration result as a loop-less weighted directed graph, thus a set of resolutions can be collected by searching for the top-k shortest paths.
Clearly finding the top-k shortest paths is a classical graph problem, and Yen’s algorithm provides the commonly-known solution. A recent and elegant discussion is proposed in .
However, I needed an implementation of this algorithm in C++ or Java. After searching Google, I could find neither. So I decided to do it myself. The initial implementation was in Java, used in our SIGMOD demo.
Afterwards, I created a Google project to share my implementation as I believe it is great if anyone can benefit from my work. Later on I added its C++ implementation per people’s requests. Actually I was surprised as so many people were interested in the project. Many of them did really apply the code to their work. More importantly, they gave me quite a few good feedbacks.

- My implementation had bugs, which were not captured in my tests. Some feedbacks helped me identify and fix most of them. Actually one bug was so tricky, because it’s hidden in the algorithm, that it was almost impossible to dig it out without users’ feedbacks.
- Some developers would like to contribute back, joining me with bug fixing, code refactoring, and even new implementation. For instance, Vinh Bui added the C# implementation.
- A small community was built up around this project, to help each other and encourage me work harder towards a better software.
Up to this point, the project became not only my own work, but one involving many minds.
I realized that the core of open source is sharing, but it should not be limited to the code only. It is more about the human minds, such as the developer experience and the user feedback.
On the other hand, the sharing should be bi-directional, thus the roles of the user and the contributor are interchangeable.
Additionally sharing can draw people together as a community, which in turn will definitely lead sharing up to a higher level.
In the sense, the philosophy advocated by open source, I believe, can be summarized as open minds.
21 Aug 2014
In 2009, I got my first full-time job with Teradata. It was a R&D position. Since then, I have migrated my focus to the parallel DBMS and the distributed computation.
Hadoop was rising as a super-star in the big data movement.
 Comparing with proprietary software, Hadoop is open source (i.e., FREE) and has an very active community, getting favors from small or middle business.
Comparing with proprietary software, Hadoop is open source (i.e., FREE) and has an very active community, getting favors from small or middle business.
However, Teradata sells its product and service, in most cases, very expensively. Most of its clients are big companies.
As one of the important players in the field, Teradata does not want to be left behind in the race, even though it does actually lead in many aspects. One big move occurred in 2011, when Teradata acquired Aster Data Systems, to address the challenge.
The common idea shared by both Hadoop and Teradata EDW (Enterprise Data Warehouse) is that data are partitioned across multiple nodes thus the computation can be done in parallel.
 Therefore one of my work then was to explore the collaboration opportunities between them.
Therefore one of my work then was to explore the collaboration opportunities between them.
-
One application was to load data from the HDFS into the Teradata data warehouse. It enables a Hadoop-Teradata EDW co-existing environment: Teradata EDW is the first tier as the data storage and for the main data analytics, whereas Hadoop is the second tier as the intermediate data storage and processing. Here Hadoop is mainly used as part of an ETL process, instead of serving for data analytics.
-
On the other hand, it is possible to run the Hadoop MapReduce job on data stored in the Teradata EDW, through the customized input format classes. Thus Hadoop provides a more flexible but maybe less efficient solution to the complex data analytics, comparing with the UDF (User Defined Function).
-
One interesting technique we developed is to optimize the data assignment from the HDFS (Hadoop File System) to the Teradata EDW, when the Hadoop and Teradata EDW are located in the same hardware cluster. It was exciting to see the problem can reduce to min-cost flow in the bipartite network.
These projects had a long-lasting influence on my career in the following years. (1) They led me into a field where thinking at scale is necessary.
(2) Another important lesson I learned is that some idea may come back and forth, like that of partitioning data for parallel computing, but people do pay more attentions to the problem it could solve. Therefore, problem-driven can be a better strategy in the field.
16 Aug 2014
When I was in college, I had a chance of working with a post-doc in our
department on the contented-based image retrieval (CBIR). Clearly it was a
hard problem. For example, not like text, it is challenging to capture the user
real intention. Moreover the image object recognition has been always an open problem.
Therefore, we proposed a different approach from the traditional submit-question-return-answer
search strategy. It is an interactive retrieval. In other words, it might not be able to return the
satisfactory result first, instead it invites the user to give its
feedback if the result is not perfect. An improved result will be given
in the following taking the user feedback into account, until the user
gets the right image, conceptually.
The tools serving our purpose included the BP neural network and the interactive genetic algorithm
(IGA).
Then ImageNet didn’t exist in those years, so in our experiments, we had to crawl
many images from the Internet. Whereas the variety was a problem as most
of the images we got were landscape photos. You can image that the
quality of our work was kind of limited.
However, working on this project was really an inspiring experience to me, as it opened a door to an unknown world where I had never been.

Another interesting project that I got involved in my graduate school in the USTC was to create a bridge health monitor system. My advisor, Professor Lu led the effort to the software development.
Tentatively I created a BP neural network to predict the bridge health . However, the performance was not good enough for the real-life application. On one hand, if the training data were not chosen properly, the result would not be right. In my experiment, there were often no enough data for the training. On the other hand, the training process was always time consuming, and not very effective.
I started realizing that the neural network might not be as effective or efficient as it does sound. It tries to simulate the way people think, but clearly there is still a long way to go before it can think like a man.