Highly Efficient User Profile Management in Petabyte-Scale Hadoop-based Data Warehouse
10 Oct 2015Traditionally the user profile data are stored and managed in the data warehouse. The user profile can be frequently updated to reflect the changes of user attribute and behavior. Moreover, it is critical to support a fast query processing for profile analytics. These basic requirements become challenging in the big data system, as the scale of profiles have reached a point (over petabytes) that the traditional data warehousing technology can barely handle.
The challenges mainly come from two aspects: the updating process is costly as the daily change can be huge and on the other hand the query performance must keep being improved as the input is rapidly increasing. For example the daily changes in the big data system can be more than terabytes, which makes data updating very expensive and often slow (big latency).
The traditional data warehouse provides a standard solution to the problem of user profile management and analytics, however the data scale that it normally deals with is not satisfactory. The data size in the traditional data warehouse is usually up to tens of terabytes. In the big data system, the petabyte-scale data store is quite normal, such that it is difficult for the traditional data warehouse to store and manage so many user profiles in an efficient way.
At Turn, we come up with an integrated solution to the highly efficient user profile management. Basically we build a data warehouse based on the Hadoop file systems. The size of data stored in the data warehouse can be on a petabyte scale. The data can be stored in row-based or columnar layouts in the data warehouse, such that it can provide both an efficient updating performance and a fast profile analytics.
Architecture
The architecture of the profile management system is mainly composed of the following components:
- Operational Data Store (ODS)
- Analytics Data Store (ADS)
- Parallel ETL
- Cluster Monitor
- Database
- Query Dispatcher
- Analytics Engine
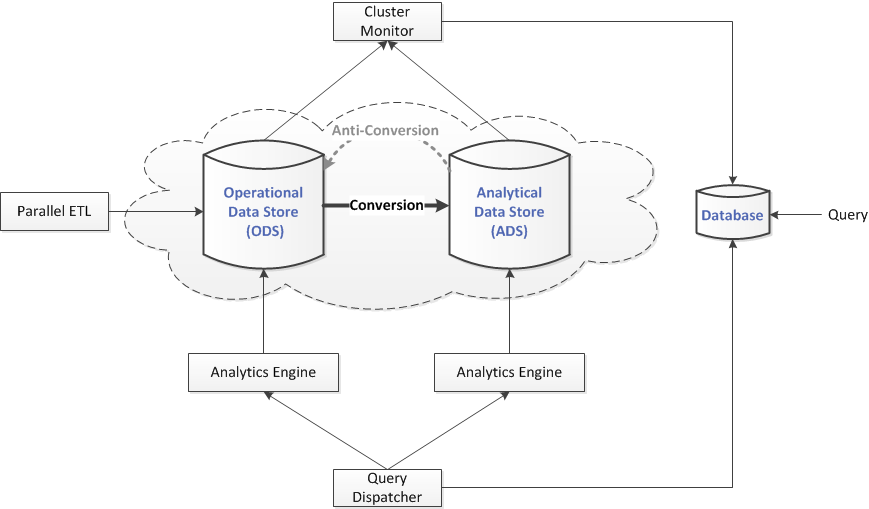
Every day there is a huge amount of data generated from the front-end system, like ad servers. The Parallel ETL (PETL) is a process running in the cluster to collect and process these data in parallel and store them in the Operational Data Store (ODS). The status of the PETL, like what data have been processed, is collected by the cluster monitor and kept in the Database.
The ODS is a row-based storage, as it must support a fast ingestion of the incoming updates. The key-value store can be faster in the data updating, however it is much slower for data analytics. In the case of profile management, the update can be merged into the profile store (i.e. ODS) regularly in batch mode. The cluster monitor collects the status of the ODS, like what data have been stored, what queries have been executed etc, and stores them in the Database.
The Analytical Data Store (ADS) provides a better solution to the data analytics. In the ADS, data are stored in columns. Comparing with its row-based counterpart (i.e., the ODS), the columnar store has a better compression ratio when storing the data, therefore has smaller data size. More importantly, only the data of interested are loaded and read when executing the user query on the columnar store. The disk I/O cost saving is almost optimal, therefore in the I/O intensive application it can achieve faster execution time in orders of magnitude comparing with the ODS. The cluster monitor collects the status of the ADS, like what data have been stored, what queries have been executed etc, and stores them in the Database.
As the data have different layouts in the ODS and the ADS, there is a data conversion from the ODS to the ADS. The conversion result is merged with the data in the ADS. Note that the ADS may not have the latest update in the ODS because the data conversion is done in batch mode. The cluster monitor collects the status of the conversion job and stores it in the Database.
When a user query is submitted, it is first stored in the query table of the Database. The query dispatcher keeps scanning the Database to (1) decide which query to execute next based on the factors, such as the waiting time, the query priority, etc, (2) decide which data store (i.e., ODS or ADS) to use for the query execution based on the data availability and the cluster resource availability, and (3) send the query job to the analytics engine for query execution.
Both the ODS and the ADS have an analytics engine to execute the query job from the query dispatcher.
The Database stores all the status information, including (1) the submitted query job, (2) the status of cluster, (3) the status of data stores (the ADS and the ODS), (4) the status of jobs running in the cluster, including the PETL, the converter, etc.