Deploy Application As Data (DaaD)
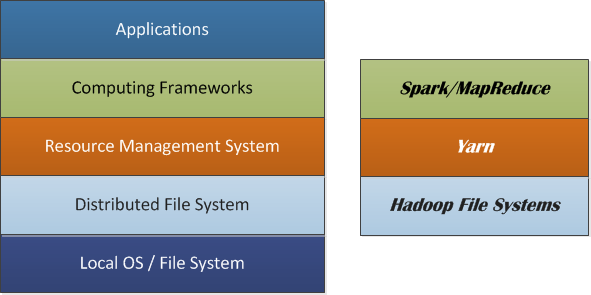
11 Nov 2015The distributed computing stack commonly uses a layered structure. A functionally independent component is defined on each layer, and different layers are connected through APIs. This structure makes it quite easy for system to scale. One example of such a system can be composed of local OS/FS, distributed FS, resource management system, distributed computing frameworks, and applications. Nowadays, the HDFS is often used as the distributed file system. Yarn is one example of the resource management systems, whereas Spark can be one of promising computing frameworks.
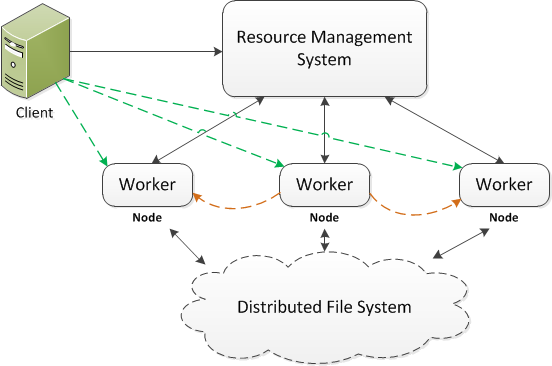
The key of distributed computing is to run the same code on the different parts of data then aggregate the results into the final solution. Particularly, the data are first partitioned, replicated and distributed across the cluster nodes. When an application is submitted, the resource management system decides how much resource is allocated and where the code can be run (usually on the nodes where the input data are stored, so called data locality). The computing framework devises a job or work plan for the application, which may be made up of tasks. More often than not a driver is issued in the client side (e.g., lines in green) or by a worker (e.g., lines in orange). The driver initializes the job and coordinates the job and task execution. Each task is executed by a worker running on the node and the result can be shuffled, sorted and copied to another node where the further execution would be done.
There are two popular ways to deploy the application code for execution.
- Deploy the code in the cluster nodes - This approach distributes the application to every node of the cluster and the client server. In other words, all involved nodes in the system have a copy of the application code. It is not common, but in some cases it is necessary when the application depends on the code running in the node. The disadvantages of this approach are obvious. First the application and the computing system have a strong coupling, such that any change from either side could potentially cause issues to the other. Second, the code deployment becomes very tedious and error prone. Think about the case where some nodes in the distributed environment fail during the code deployment. The state of cluster becomes unpredictable when those failed nodes come alive with the old version of code.
- Deploy the code in the client only - A more common strategy is to deploy the application code to client server only. When running the application, the code is first distributed to the cluster nodes with some caching mechanism, such as the distributed cache in the Hadoop. This simple but effective approach could decouple the application and its underneath computing framework very well. However when the number of clients is large, the deployment can become nontrivial. Also if the size of application is very large, the job may have a long initialization process as the code needs distributing across the cluster.
DaaD: Deploy Application As Data
In the distributed computing, the code and the data are traditionally treated differently. The data can be uploaded to the cloud and then copied and distributed by means of the file system utilities. However the code deployment is usually more complex. For example the network topology of application nodes must be well defined beforehand. A sophisticated sync-up process is often required to ensure the consistency and efficiency, especially when the number of application nodes is large.
Therefore if the code can be deployed as data (i.e., DaaD), the code deployment can be much simpler. The DaaD is a two-phase process.
- The application code is uploaded to the distributed file system just as common data files.
- When running the application, a launcher is used to load the code from the distributed file system, store the code in the distributed cache accessible to all nodes and issue the execution on node.
Clearly, the launcher is required to deployed to the client where the execution request is submitted. It should be independent of any specific applications. An example can be found at DaaD1.
The improvement by the DaaD can be significant.
-
The deployment becomes much simpler. Often the code can be uploaded to the distributed file system through a simple command. Then the code replicating and distributing can be achieved automatically through the file system utilities.
-
The launcher can be defined as a simple class or executable file, which is quite stable. It is trivial to distribute it to the application node.
-
The application code is loaded for execution only if an execution request is issued. Namely the code is actually copied and distributed in the lazy way. Importantly the latest version of code is always used.
-
Having no local copy can avoid of code inconsistency problem.
-
It makes it much easier for different code versions coexist in production. Image the scenario where it is necessary to run the same application with different code versions for A-B test.
-
DaaD - https://github.com/turn/DaaD ↩